

Job queues help manage workload, handle traffic spikes, and keep a system reliable. But what happens when your queue system itself becomes a source of complexity?
At OpenPanel, we process millions of analytics events daily. Each event needs to be queued, processed, and stored efficiently. We started with BullMQ, which served us well initially. However, as our traffic grew, we hit a problem that many high-throughput systems face: race conditions when processing related events.
The concurrency problem
Imagine you're tracking user behavior on a website. A single user might trigger multiple events within milliseconds: a page view, a click, and a form submission. These events arrive at your queue almost simultaneously, and if processed in parallel by different workers, they can create race conditions.
Traditional solutions involve complex locking mechanisms, distributed locks, or careful transaction management. While these work, they add complexity and can become bottlenecks themselves. We needed something better.
The ideal solution was clear: process events from the same user sequentially while maintaining overall system throughput. This would eliminate race conditions at the architectural level rather than trying to handle them in application code.
Why not BullMQ Pro?
BullMQ actually offers this exact feature through their "Group" functionality, but it's only available in their Pro version. For a commercial SaaS product, paying for BullMQ Pro makes perfect sense. However, OpenPanel is open source and self-hostable.
Requiring our users to buy a commercial license for a core dependency would contradict our mission. We want to provide a complete, open-source analytics solution that anyone can run without hidden costs or proprietary dependencies.
So we built GroupMQ: an open-source queue system that makes job grouping a first-class feature instead of a premium add-on.
Introducing GroupMQ
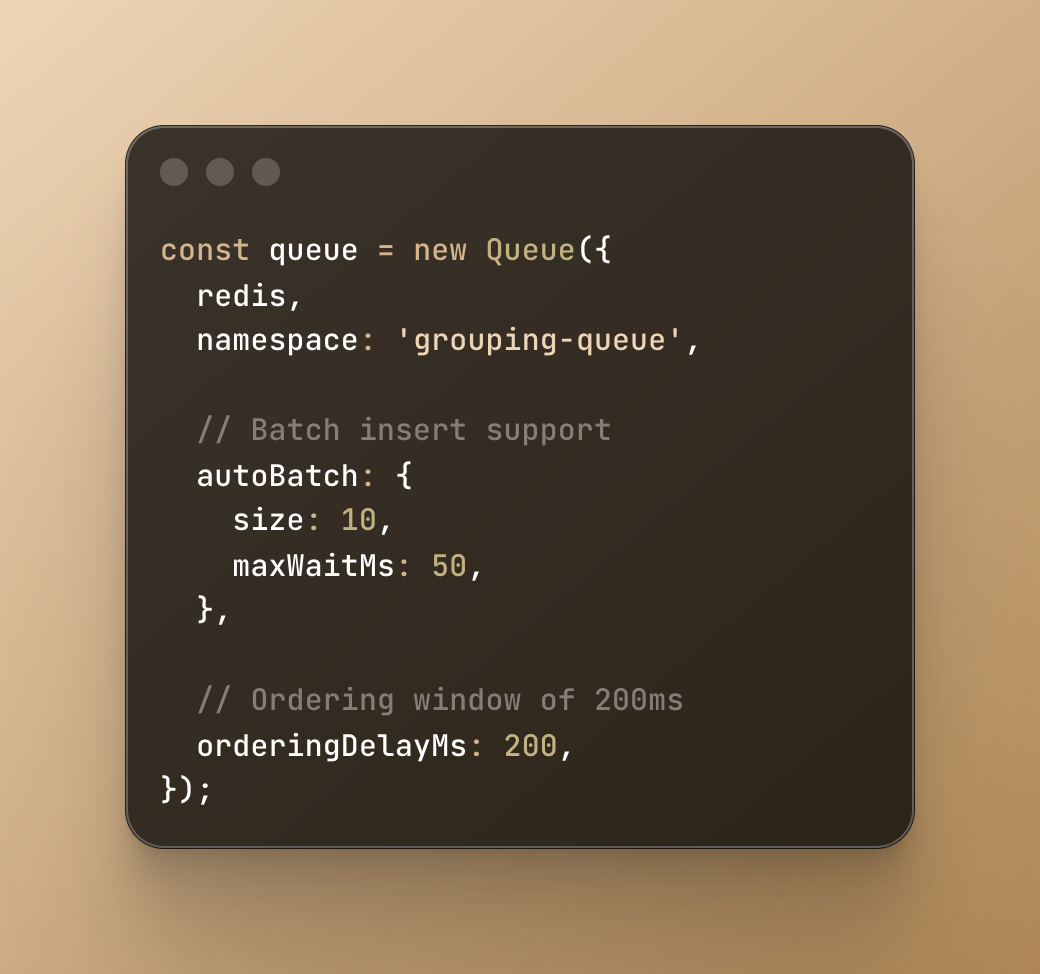
GroupMQ is a Redis-based queue system inspired by BullMQ but designed from the ground up with job grouping as its core feature. It ensures that jobs within the same group are processed sequentially while different groups run in parallel.
Here's what GroupMQ does:
Group processing: Jobs are automatically organized by group IDs. The system guarantees that only one job per group is processed at any given time, which eliminates race conditions for related operations.
Fair scheduling: Unlike naive implementations that might let one busy group block others, GroupMQ uses a round-robin approach so all groups get processing time. This prevents any single group from monopolizing worker resources.
Familiar API: If you've used BullMQ, you'll feel at home. We've kept similar patterns and conventions, which makes migration straightforward. The main difference is that group assignment is mandatory and built into every operation.
Redis-native performance: Built directly on Redis data structures, GroupMQ uses Redis's atomic operations for performance and reliability. There's no additional overhead compared to other Redis-based queues.
Real-world use cases
GroupMQ fits cases where you need to maintain order within related operations:
Analytics processing: Process events from the same user sequentially to maintain accurate session tracking and prevent duplicate counting.
E-commerce orders: Handle order updates, payment processing, and inventory changes for the same order ID without race conditions.
Notification systems: Process notifications for the same recipient in order, preventing out-of-sequence messages.
Multi-tenant applications: Process jobs for each tenant in isolation while maintaining overall system throughput.
Import/export operations: Handle file processing where multiple operations on the same resource must happen sequentially.
BullBoard compatibility
One of BullMQ's strengths is its tooling, particularly BullBoard for queue monitoring. GroupMQ stays compatible with BullBoard through an adapter.
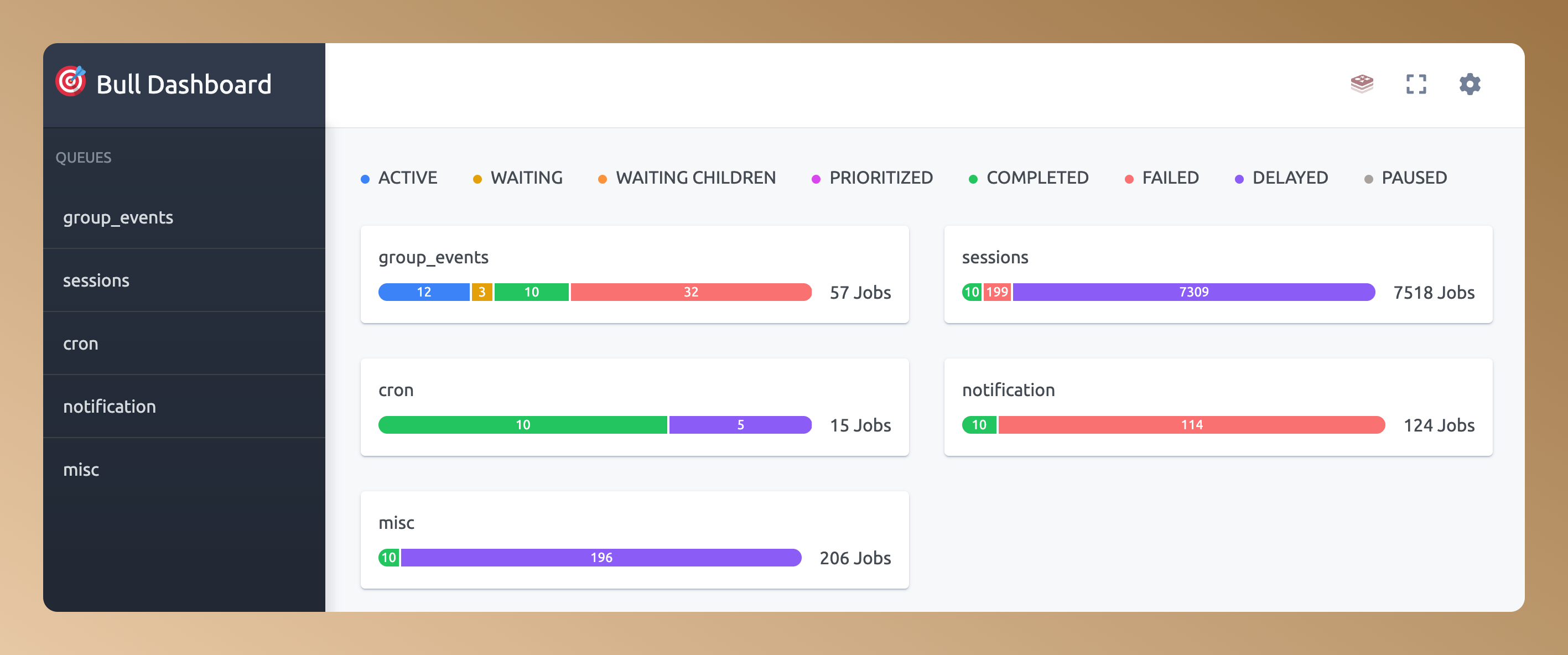
This means you can continue using your existing monitoring setup. View job counts, processing rates, and failed jobs just as you would with BullMQ. The only difference is that jobs are now organized by groups, giving you better visibility into your grouped processing patterns.
Migration from BullMQ
Migrating from BullMQ to GroupMQ takes a few changes:
-
Adding Group IDs: Every job must have a group ID. This is typically derived from your existing data (user ID, order ID, etc.)
-
Updating Job Addition: Update
queue.add()to includegroupIdin the options object -
Worker Updates: Workers now receive job objects with both
dataandgroupIdproperties
Here's a quick example of the differences:
// BullMQ
import { Queue, Worker } from 'bullmq';
import IORedis from 'ioredis';
const connection = new IORedis({ maxRetriesPerRequest: null });
const queue = new Queue('events');
await queue.add('process-event', { userId: 123, action: 'click' });
const worker = new Worker(
'events',
async (job) => {
console.log(job.data); // { userId: 123, action: 'click' }
},
{ connection }
);
// GroupMQ
import Redis from 'ioredis';
import { Queue, Worker } from 'groupmq';
const redis = new Redis();
const queue = new Queue({ redis, namespace: 'events' });
await queue.add({
groupId: 'user-123',
data: { userId: 123, action: 'click' }
});
const worker = new Worker({
queue,
handler: async (job) => {
console.log(job.data); // { userId: 123, action: 'click' }
console.log(job.groupId); // 'user-123'
},
});
worker.run();The main differences are:
- Queue constructor: BullMQ takes a queue name string, GroupMQ takes an options object with
redisandnamespace - Adding jobs: BullMQ takes job name and data as separate parameters, GroupMQ takes a single object with
groupIdanddata - Workers: BullMQ takes queue name, handler function, and options. GroupMQ takes an options object with
queueandhandler, then requires callingrun() - Job object: GroupMQ jobs include both
job.dataandjob.groupIdproperties
Performance characteristics
GroupMQ's performance profile differs from traditional queues:
Sequential within groups: Jobs in the same group process one at a time. This might seem like a limitation, but it's what prevents race conditions. The throughput for a single group matches single-threaded processing speed.
Parallel across groups: Different groups process in parallel. With enough groups, you can saturate all available workers like a traditional queue system.
Predictable latency: Since groups process independently, a slow job in one group doesn't impact others. This isolation makes performance more predictable.
Memory efficiency: Group organization in Redis is optimized to minimize memory usage while keeping fast access patterns.
Advanced features
Beyond basic job grouping, GroupMQ includes:
Delayed jobs: Schedule jobs to run after a specific delay, useful for scheduled tasks or retry backoffs.
Repeating jobs: Configure cron-like patterns to create recurring jobs on a schedule.
Job retries: Built-in retry mechanism with configurable attempts and backoff strategies. Failed jobs can be automatically retried or moved to dead letter storage.
Ordering strategies: Choose between different ordering methods ('none', 'scheduler', or 'in-memory') to handle out-of-order job arrivals based on your use case.
Graceful shutdown: Workers can complete processing current jobs before shutting down, keeping data consistent.
BullBoard integration: Monitor your queues using the BullBoard interface through the provided adapter.
When to choose GroupMQ
GroupMQ is the right choice when:
- You need to process related jobs sequentially
- Race conditions are a concern in your system
- You want to eliminate complex locking logic
- Your workload naturally groups into independent streams
- You're building an open-source project and need a fully open queue solution
It might not be the best fit if:
- Your jobs are completely independent
- You need every job to process as fast as possible regardless of relationships
- You have very few natural groupings in your data
- You're already using BullMQ Pro and happy with it
Getting started
Installing GroupMQ:
npm install groupmqBasic usage:
import Redis from 'ioredis';
import { Queue, Worker } from 'groupmq';
const redis = new Redis();
const queue = new Queue({
redis,
namespace: 'events',
});
// Add a job to a group
await queue.add({
groupId: 'user-123',
data: { userId: 123, action: 'pageview' }
});
// Process jobs with a worker
const worker = new Worker({
queue,
handler: async (job) => {
console.log(`Processing ${job.data.action} for ${job.groupId}`);
// Your processing logic here
},
});
worker.run();Open source philosophy
GroupMQ is fully open source. It's MIT licensed, accepts community contributions, and will never have a "pro" version with essential features locked away.
We built GroupMQ because we needed it for OpenPanel, but we're releasing it as a standalone project because others face the same problem.
